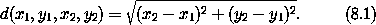
|
一个恰当的记号体系至少应能被两人理解,其中一人可以是作者本人。
Abdus Salam (1950)。
|
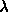 -演算[13],直接支持函数的操作。我们为 Scheme 添加了符号、数值和泛型特性以支持我们的应用。关于 Scheme 的简单介绍,请参见 Scheme 附录。数学记号与 Scheme 之间的对应关系要求数学表达式是無歧义且自包含的。Scheme 为验证数学推导提供了即时反馈,并有助于探索系统的行为。
-演算[13],直接支持函数的操作。我们为 Scheme 添加了符号、数值和泛型特性以支持我们的应用。关于 Scheme 的简单介绍,请参见 Scheme 附录。数学记号与 Scheme 之间的对应关系要求数学表达式是無歧义且自包含的。Scheme 为验证数学推导提供了即时反馈,并有助于探索系统的行为。
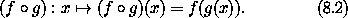
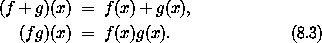


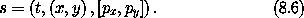
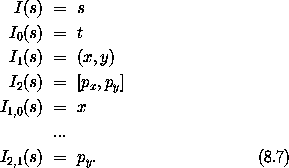
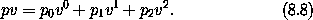
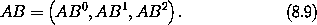
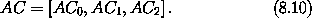

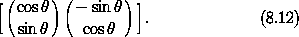
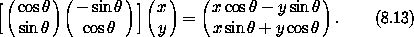
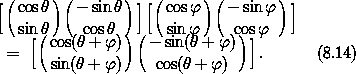
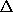 x 以得到 f 值增量的线性近似:
x 以得到 f 值增量的线性近似:
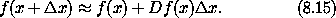 x 处的值为
x 处的值为
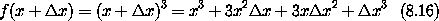
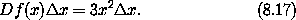 x 给出了 f(x + x) 中关于 x 的线性项,当 x 很小时,它提供了 f(x + x) - f(x) 的良好近似。
复合函数的导数遵循链式法则:
x 给出了 f(x + x) 中关于 x 的线性项,当 x 很小时,它提供了 f(x + x) - f(x) 的良好近似。
复合函数的导数遵循链式法则:
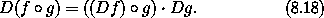
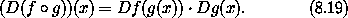
x, y ),我们计算:
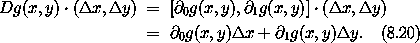


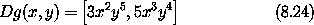 x 和 y 时增量的一阶近似为
x 和 y 时增量的一阶近似为
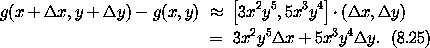
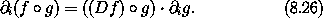
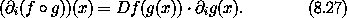
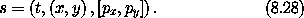
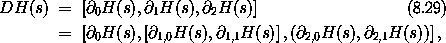
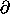 1,0 表示函数关于第二个自变量(索引 1)的第一个分量(索引 0)的偏导数,以此类推。确实,对于任何函数 F 和存取链 z,有 z F = Iz o D F。因此,如果我们令 s 为一个增量相空间状态元组,
1,0 表示函数关于第二个自变量(索引 1)的第一个分量(索引 0)的偏导数,以此类推。确实,对于任何函数 F 和存取链 z,有 z F = Iz o D F。因此,如果我们令 s 为一个增量相空间状态元组,
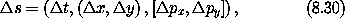
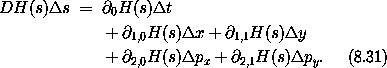
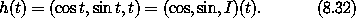
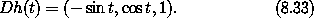
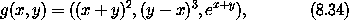
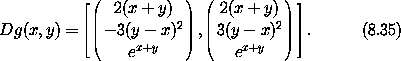
练习 8.1. 链式法则 令 F(x, y) = x2 y3, G(x, y) = (F(x, y), y), H(x, y) = F(F(x, y), y),因此 H = F o G。 a. 计算
0 F(x, y) 和 1 F(x, y)。
b. 计算 0 F(F(x, y), y) 和 1 F(F(x, y), y)。
c. 计算 0 G(x, y) 和 1 G(x, y)。
d. 计算 DF(a, b), DG(3, 5) 和 DH(3a2, 5b3)。
练习 8.2. 计算导数 我们可以通过多种方式将多自变量函数表示为过程,具体取决于我们希望如何使用它们。最简单的方式是将过程的自变量与函数的自变量等同起来。 例如,我们可以按如下方式编写练习 8.1 中出现的函数的实现: (define (f x y)
 , sin ), ( - sin, cos ) ]。
, sin ), ( - sin, cos ) ]。